
DynamoDB でスロットリングエラーを発生させてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コーヒーが好きな emi です。
DynamoDB の性能がなかなか思うように上がらず、パフォーマンス向上のため環境調査をしていたところ、スロットリングが発生していることに気が付きました。
スロットリング (throttling) とは、システムの過負荷や特定のアクセスによるリソース独占を回避するため、一定の制限値を超えた場合に意図的に性能を低下させたり、要求を一時的に拒否したりする制御のことです。
DynamoDB のスロットリングの仕組みについて理解するために、意図的にスロットリングを発生させてみました。
構成図
今回は Lambda から DynamoDB に大きなサイズのアイテム書き込み(PutItem)を行い、意図的にスロットリングエラーを発生させます。
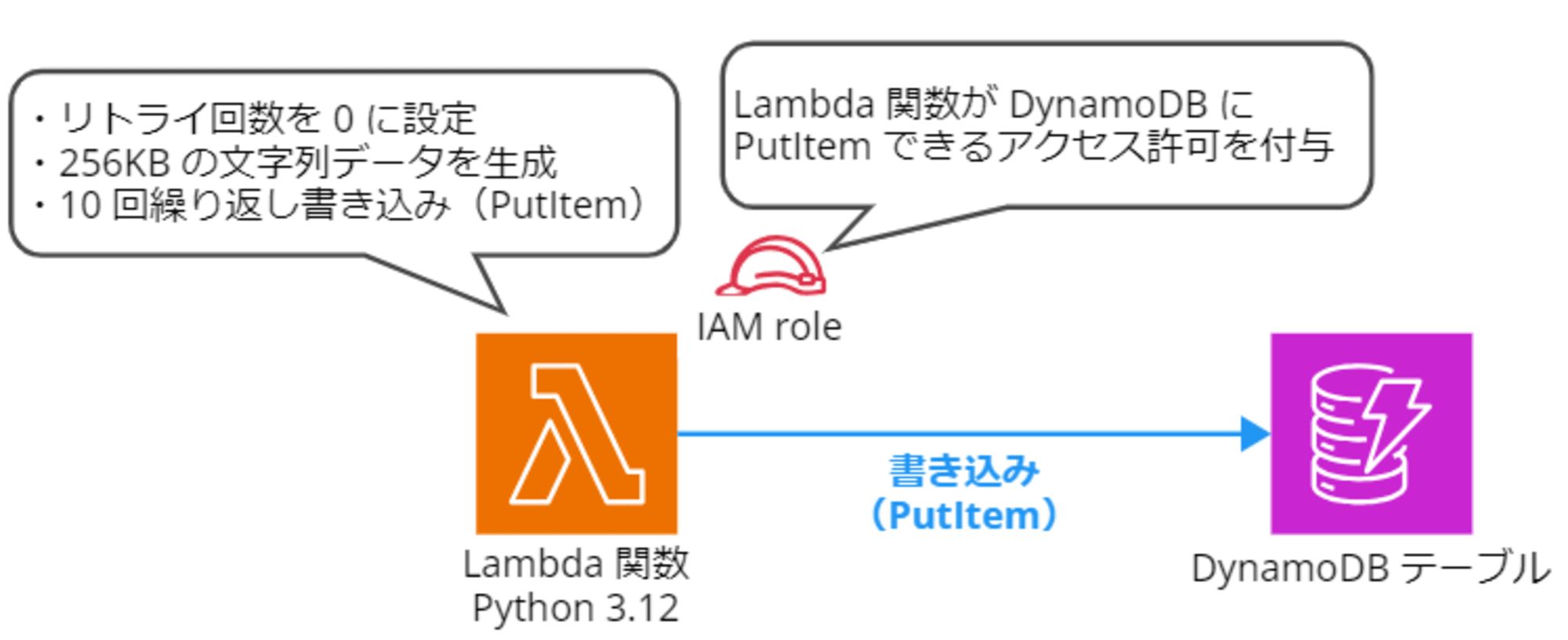
スロットリングさせる際の考慮事項
詳細は検証手順の中で再度案内しますが、特に以下 3 点考慮します。
- 1. 意図的にスロットリングさせるため、DynamoDB テーブルのスペックは固定(プロビジョンドモード)で低く設定する
- 十分なキャパシティユニットが確保されているとスロットリングが発生しません。オンデマンドモードや AutoScalling が有効になっているとキャパシティユニットが確保されてしまうためスロットリングが発生しません。
- 2. DynamoDB にはバーストキャパシティがあるため、スロットリングさせる場合は書き込むアイテムのサイズを十分に大きくする
- DynamoDB には バーストキャパシティ という仕組みがあり、利用可能なスループットを使い切っていない場合、キャパシティの未使用分を最大 5 分 (300 秒) 蓄えておき、後のスループットのバースト(スパイク)時に消費することで対応します。
- つまり、低く設定した WCU や RCU を少し上回るくらいでは貯蓄された余剰キャパシティを消費することによりスロットリングが発生しません。
- 書き込むアイテムのサイズは十分に大きくし、できれば繰り返し書き込むことでスロットリング発生確率を高くします。
- 3. Boto3 の再実行ロジックを明示的に無効にする(リトライを 0 回に指定する)
- AWS SDK には実行時のエラーを受け取った際の再試行ロジックが最初から自動で実装されており、ユーザーが明示的にリトライロジックを組まなくても各リソースのデフォルトで設定された回数分はエクスポネンシャルバックオフによるリトライ処理が実施されます。
- よって、今回はスロットリングを発生させるためデフォルトのリトライ回数を 0 回に変更します。
DynamoDB テーブルの作成
DynamoDB テーブルを作成します。
テーブル名は「throttled-test」、パーティションキーは throttled-test-key としました。
1. 意図的にスロットリングさせるため、DynamoDB テーブルのスペックは固定(プロビジョンドモード)で低く設定する
意図的にスロットリングさせるため、DynamoDB テーブルのスペックは固定で低く設定します。
キャパシティモードはプロビジョンドモードにし、Auto Scaling はオフにします。
- プロビジョンされた読み込みキャパシティーユニット(RCU):1
- プロビジョンされた書き込みキャパシティーユニット(WCU):1
ちなみに、オンデマンドモードで作成した DynamoDB テーブルをプロビジョンドモードに変更すると、21~22 時間程度オンデマンドモードに戻せなくなります。
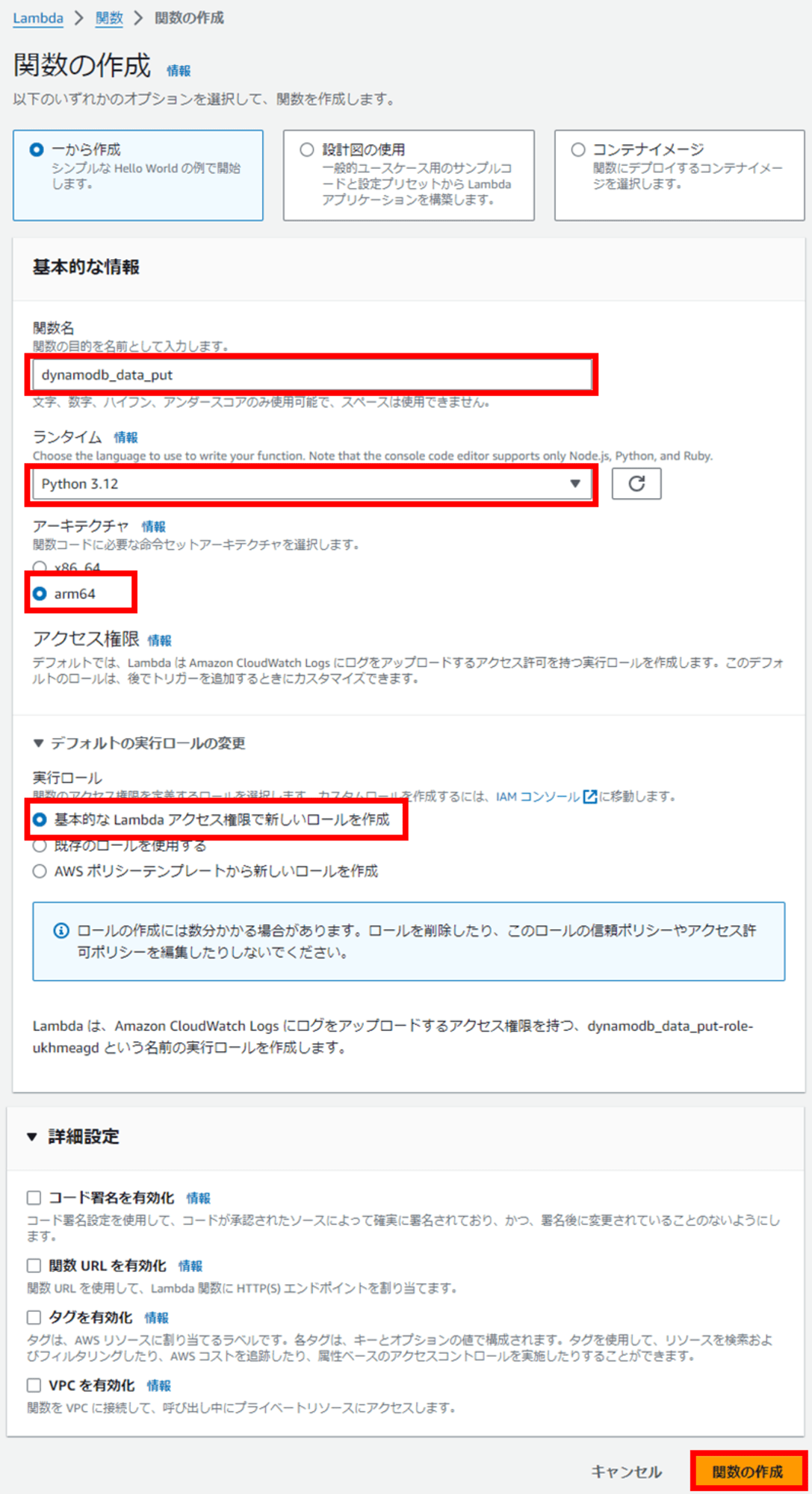
Lambda 関数の作成
DynamoDB にレコードを書き込む Lambda 関数を作成します。
関数名は「dynamodb_data_put」とし、ランタイムは Python 3.12 にしました。アーキテクチャはコストを抑えるため arm64 にしてみました。
デフォルトの実行ロールは「基本的な Lambda アクセス権限で新しいロールを作成」で進めます。後ほど DynamoDB への書き込み権限を追加します。
他はデフォルト設定のまま、関数を作成します。
Lambda 関数に DynamoDB への書き込み権限を付与
DynamoDB にアイテムを書き込むための PutItem アクション許可を追加します。
IAM コンソールで以下のような新規カスタム管理ポリシーを作成してください。今回ポリシー名は「dynamodb_data_put-policy」としました。
arn:aws:dynamodb:ap-northeast-1:123456789012:table/throttled-test には自身が作成した DynamoDB テーブルの ARN を入れます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "dynamodb:PutItem",
"Resource": "arn:aws:dynamodb:ap-northeast-1:123456789012:table/throttled-test"
}
]
}
Lambda コンソールに戻り、作成した Lambda 関数「dynamodb_data_put」をクリックし、[設定]タブ - [アクセス権限] からロール名のリンクをクリックして IAM ロールの画面に遷移します。
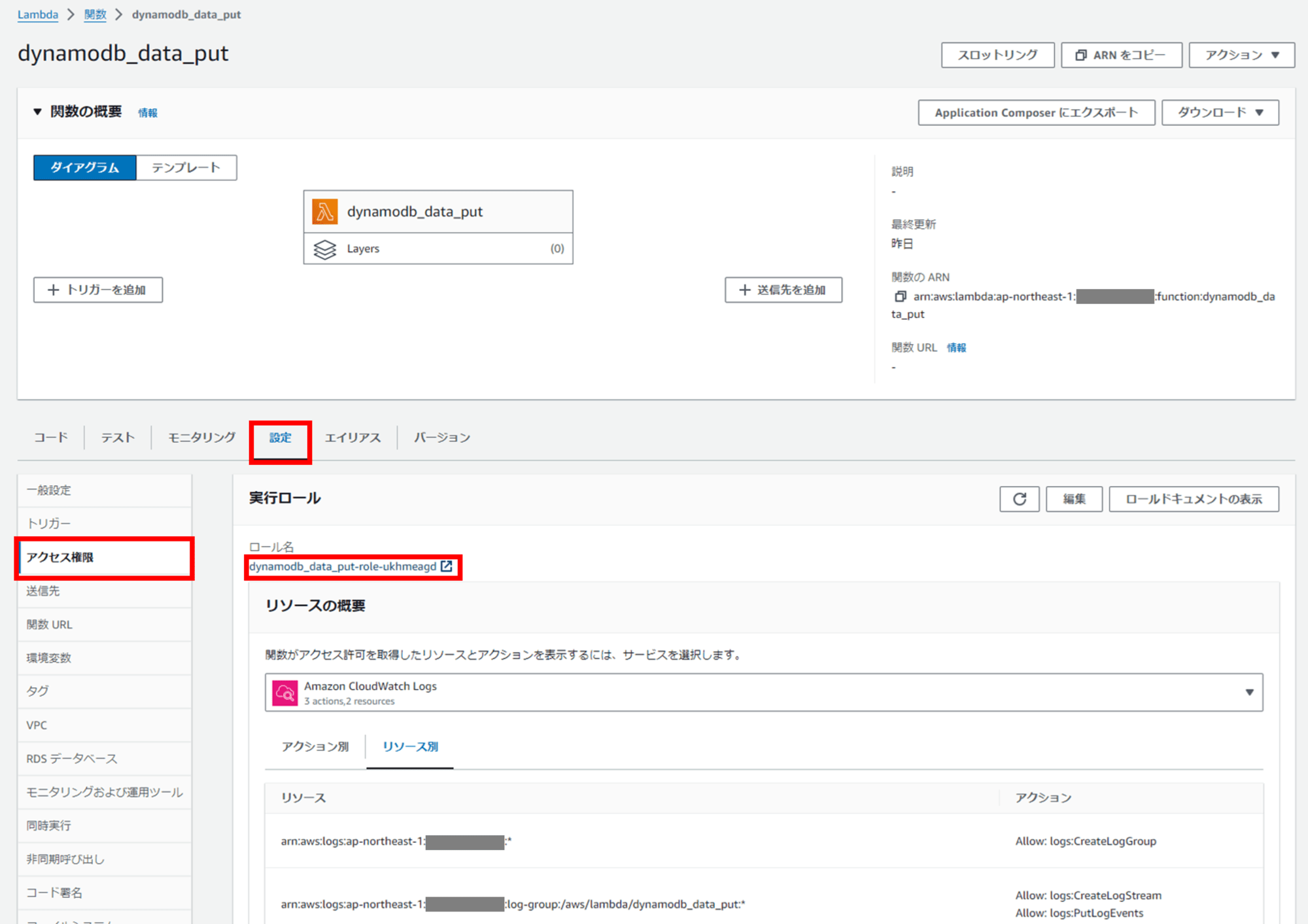
あらかじめ作成しておいたカスタム管理ポリシー「dynamodb_data_put-policy」を、Lambda の実行ロールにアタッチします。
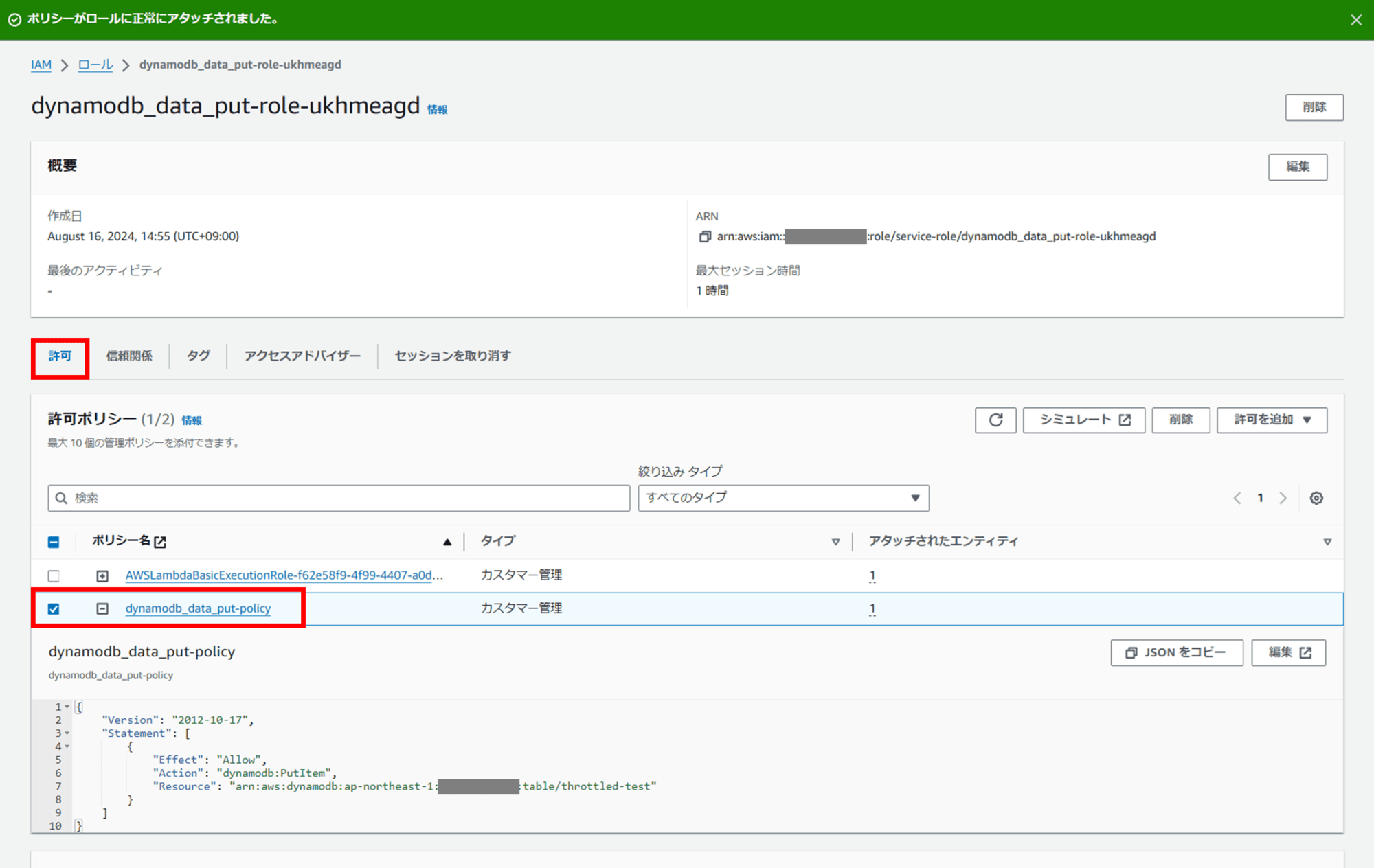
これで、Lambda 関数から DynamoDB にアイテムを書き込むことができるようになりました。
DynamoDB に PutItem する Python コードの作成
今回は Python 3.12 を使用します。Python で DynamoDB を使用する方法は以下のドキュメントが参考になります。
以下のコードを「lambda_function.py」に貼り付けます。
import json
import random
import string
from botocore.client import Config
import boto3
# リトライ回数を 0 に設定
config = Config(
retries={
'max_attempts': 0 # リトライ回数を 0 に設定
}
)
# boto3 を使用して DynamoDB クライアントを作成(初期化)
dynamodb_client = boto3.client(
'dynamodb',
config=config,
region_name='ap-northeast-1'
)
# 大きなサイズのデータを生成する関数を定義
def generate_large_data(size_in_kb):
# ASCII 文字と数字を組み合わせて指定サイズのデータを生成
# size_in_kb は生成するデータのサイズを KB 単位で指定
return ''.join(random.choices(string.ascii_letters + string.digits, k=size_in_kb * 1024))
# データを生成
data = generate_large_data(256) # 256KB のデータを生成
i = 0 # カウンタを初期化
# スロットリングを発生させるために、同じテーブルに複数のアイテムを書き込む
while i < 10:
item = {
'throttled-test-key': {'S': f'aaa-{i}'}, # S で String 型を指定、各アイテムにユニークなパーティションキーを設定。パーティションキーは throttled-test-key (String) でテーブルに作成済み
'foo': {'S': data} # 生成した 256KB のデータを設定
}
# DynamoDB に書き込みを実行
dynamodb_client.put_item(
TableName='throttled-test',
Item=item
)
print(f'Item{i}written')
i += 1
コードの解説
DynamoDB に対するアクセスには boto3 の client を使用してみました。
# boto3 を使用して DynamoDB クライアントを作成(初期化)
dynamodb_client = boto3.client(
'dynamodb',
config=config,
region_name='ap-northeast-1'
)
2. DynamoDB にはバーストキャパシティがあるため、スロットリングさせる場合は書き込むアイテムのサイズを十分に大きくする
DynamoDB には バーストキャパシティ という仕組みがあり、利用可能なスループットを使い切っていない場合、キャパシティの未使用分を最大 5 分 (300 秒) 蓄えておき、後のスループットのバースト(スパイク)時に消費することで対応します。低く設定した WCU や RCU を少し上回るくらいでは貯蓄された余剰キャパシティを消費することによりスロットリングが発生しないため、書き込むアイテムのサイズは十分に大きくし、繰り返し書き込むようにします。
データ生成のために Python 標準ライブラリの random と string を使います。
# 大きなサイズのデータを生成する関数を定義
def generate_large_data(size_in_kb):
# ASCII 文字と数字を組み合わせて指定サイズのデータを生成
# size_in_kb は生成するデータのサイズを KB 単位で指定
return ''.join(random.choices(string.ascii_letters + string.digits, k=size_in_kb * 1024))
# データを生成
data = generate_large_data(256) # 256KB のデータを生成
生成した 256KB の文字列を、アイテムとしてテーブルに 10 回書き込んでいきます。パーティションキー throttled-test-key に入る文字列は各アイテムで被らないように i += 1 しながら繰り返します。
i = 0 # カウンタを初期化
# スロットリングを発生させるために、同じテーブルに複数のアイテムを書き込む
while i < 10:
item = {
'throttled-test-key': {'S': f'aaa-{i}'}, # S で String 型を指定、各アイテムにユニークなパーティションキーを設定。パーティションキーは throttled-test-key (String) でテーブルに作成済み
'foo': {'S': data} # 生成した 256KB のデータを設定
}
# DynamoDB に書き込みを実行
dynamodb_client.put_item(
TableName='throttled-test',
Item=item
)
print(f'Item{i}written')
i += 1
今回 DynamoDB テーブル作成の際、プロビジョンドキャパシティを WCU = 1 としました。最大サイズが 1 KB の項目について 1 秒あたり 1 回の書き込みで 1WCU 消費しますから、256KB を 1 アイテムに突っ込もうとすればそれだけで 256WCU 消費します。バーストキャパシティも尽きるはずです。
さらにそれを 10 回繰り返そうものなら、きっとひとたまりもなくスロットリングしてくれることでしょう。
ちなみに DynamoDB には以下のクォーターがあるので、指定する文字列のサイズは大きすぎないようにします。
- アイテムの最大サイズは 400 KB
- クエリやスキャンの response サイズは 1MB
3. Boto3 の再実行ロジックを明示的に無効にする(リトライを 0 回に指定する)
AWS SDK には実行時のエラーを受け取った際の再試行ロジックが最初から自動で実装されており、ユーザーが明示的にリトライロジックを組まなくても各リソースのデフォルトで設定された回数分はエクスポネンシャルバックオフによるリトライ処理が実施されます。
すごい、便利ですね!
botocore のソースコードを見ると "max_attempts": 5, となっており、既定のリトライ回数は 5 回です。
とっても便利な仕組みなのですが、今回はスロットリングを意図的に発生させるために、このリトライ回数を 0 回に変更しておきます。
# リトライ回数を 0 に設定
config = Config(
retries={
'max_attempts': 0 # リトライ回数を 0 に設定
}
)
リトライ回数の設定方法は下記記事を参照ください。
スロットリングを発生させる
準備ができたので Lambda 関数を実行し、DynamoDB テーブルに書き込みを行います。
Lambda コンソールで「テスト」タブを開き、「テスト」をクリックします。
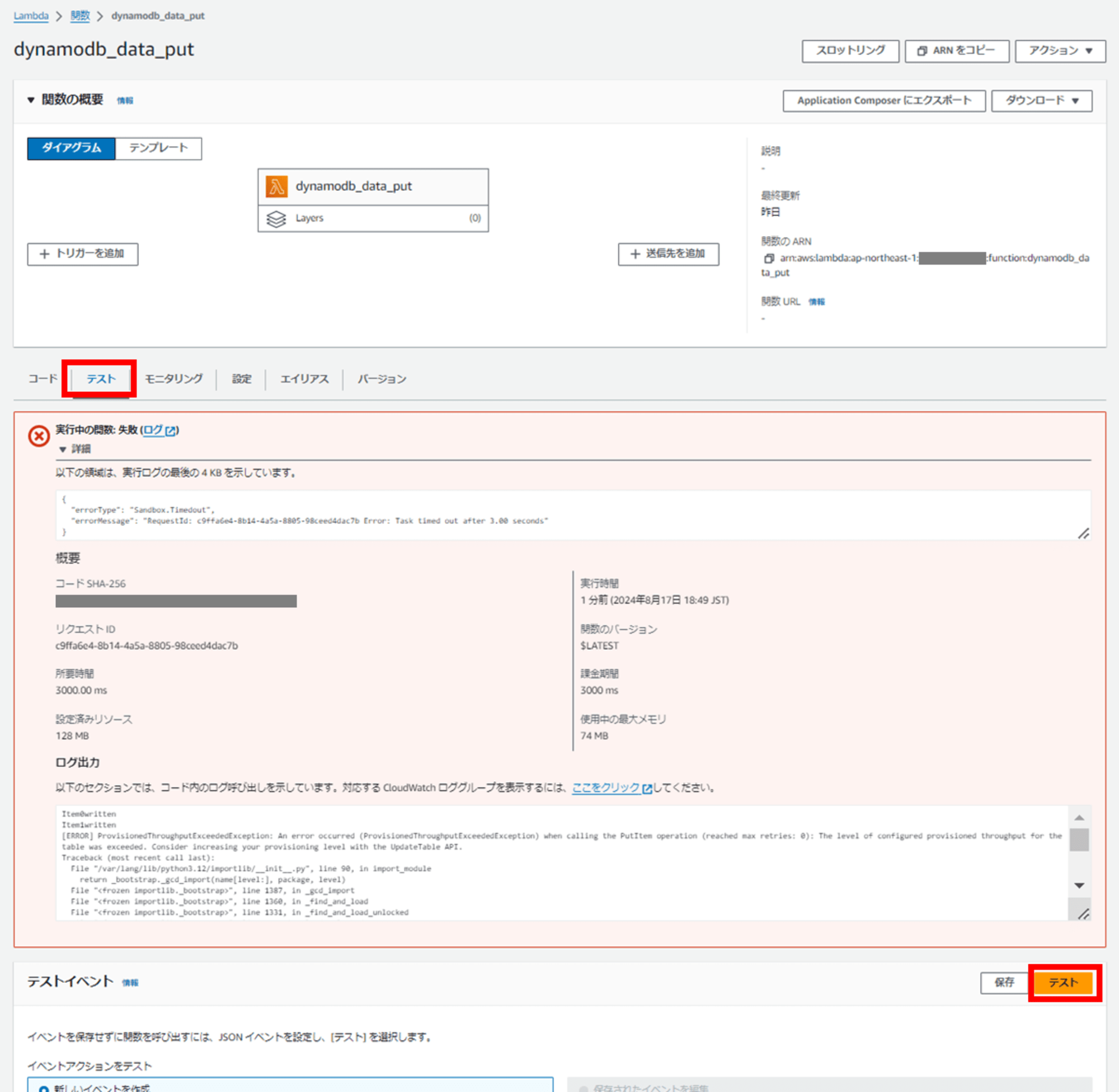
エラーになりました。
赤枠の一番上に表示される実行ログの最後の 4KB の部分を見ると、3 秒でタイムアウトした旨が確認できます。
下部の「ログ出力」部分を見ると、[ERROR] ProvisionedThroughputExceededException: と表示されている行があります。
良いですね。これは想定通りスロットリングが起こったログです。
Item0written
Item1written
[ERROR] ProvisionedThroughputExceededException: An error occurred (ProvisionedThroughputExceededException) when calling the PutItem operation (reached max retries: 0): The level of configured provisioned throughput for the table was exceeded. Consider increasing your provisioning level with the UpdateTable API.
Traceback (most recent call last):
File "/var/lang/lib/python3.12/importlib/__init__.py", line 90, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1387, in _gcd_import
File "<frozen importlib._bootstrap>", line 1360, in _find_and_load
File "<frozen importlib._bootstrap>", line 1331, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 935, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 995, in exec_module
File "<frozen importlib._bootstrap>", line 488, in _call_with_frames_removed
File "/var/task/lambda_function.py", line 39, in <module>
dynamodb_client.put_item(
File "/var/lang/lib/python3.12/site-packages/botocore/client.py", line 565, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/var/lang/lib/python3.12/site-packages/botocore/client.py", line 1021, in _make_api_call
raise error_class(parsed_response, operation_name)INIT_REPORT Init Duration: 809.64 ms Phase: init Status: error Error Type: Runtime.Unknown
INIT_REPORT Init Duration: 3026.47 ms Phase: invoke Status: timeout
START RequestId: c9ffa6e4-8b14-4a5a-8805-98ceed4dac7b Version: $LATEST
END RequestId: c9ffa6e4-8b14-4a5a-8805-98ceed4dac7b
REPORT RequestId: c9ffa6e4-8b14-4a5a-8805-98ceed4dac7b Duration: 3000.00 ms Billed Duration: 3000 ms Memory Size: 128 MB Max Memory Used: 74 MB Status: timeout
Lambda のログが保存されている CloudWatch Log グループ /aws/lambda/dynamodb_data_put で詳細な情報も確認できます。
一番上の最新のログストリームを見てみましょう。
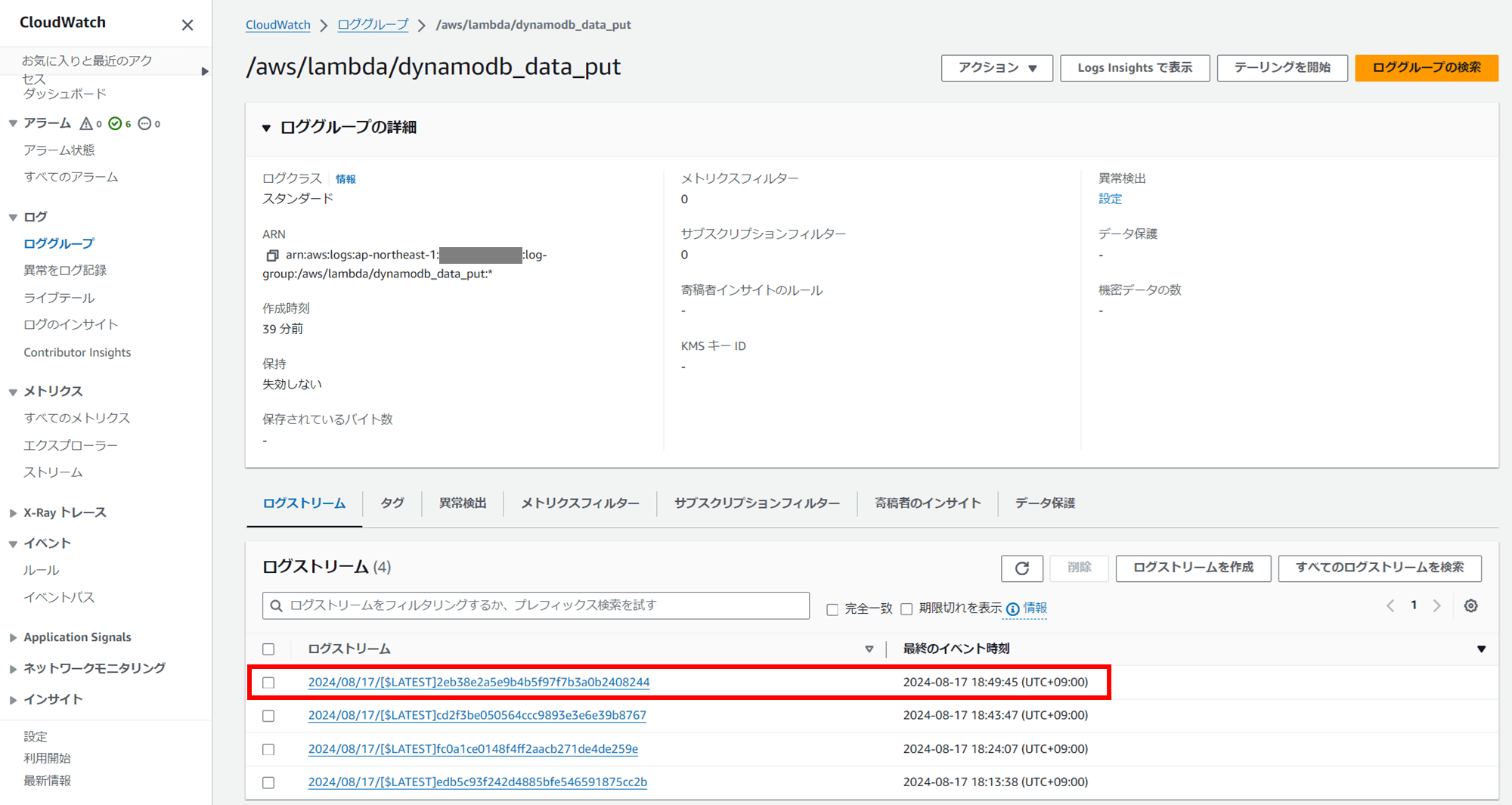
以下のことが読み取れます。
- Item0written と Item1written で 2 アイテムが正常に書き込まれている
[ERROR] ProvisionedThroughputExceededExceptionで、PutItem操作の際プロビジョニングされたスループットを超え、書き込みが失敗しているREPORT ~ Duration: 3000.00 ms Billed Duration: 3000 ms ~ Status: timeoutで Lambda 関数がタイムアウト(3000ms)に達し途中で処理が終了
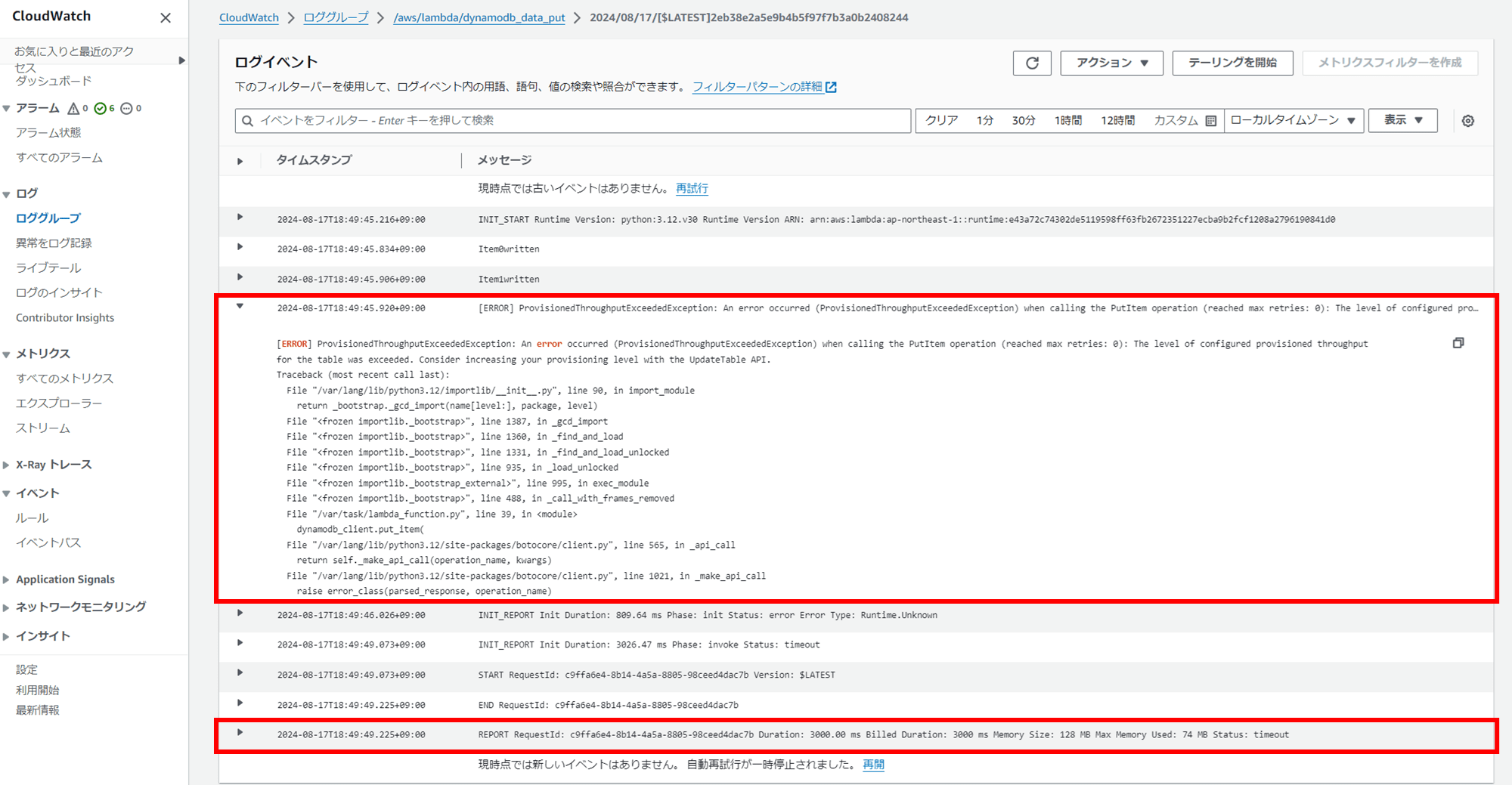
2 アイテム書き込みを行ったところでスロットリングが発生し、そのまま Lambda 関数のデフォルトタイムアウト時間 3 秒(3000ms)が経過して実行が終わったということですね。
プロビジョンドキャパシティで WCU = 1 としているテーブルで 256KB の文字列を 2 回も書き込めているので、計算上 512 WCU は消費したはずです。バーストキャパシティは侮れませんね。
DynamoDB テーブル「throttled-test」の概要タブ下部で、キャパシティメトリクスを見てみましょう。
書き込み使用量 (平均単位/秒)(Write usage (average units/second))グラフで、プロビジョンドされている 1WCU の赤いラインを、実際に消費した WCU の青いラインが大幅に超えている瞬間があるのが分かります。二回超えていますが、これは私が二回 Lambda 関数をテスト実行したからです。
書き込み調整されたリクエスト (数)(Write throttled requests (count))グラフが、スロットリングしたリクエストの回数です。PutItem を示す青いラインが表示され、スロットリングが発生しているのが分かります。
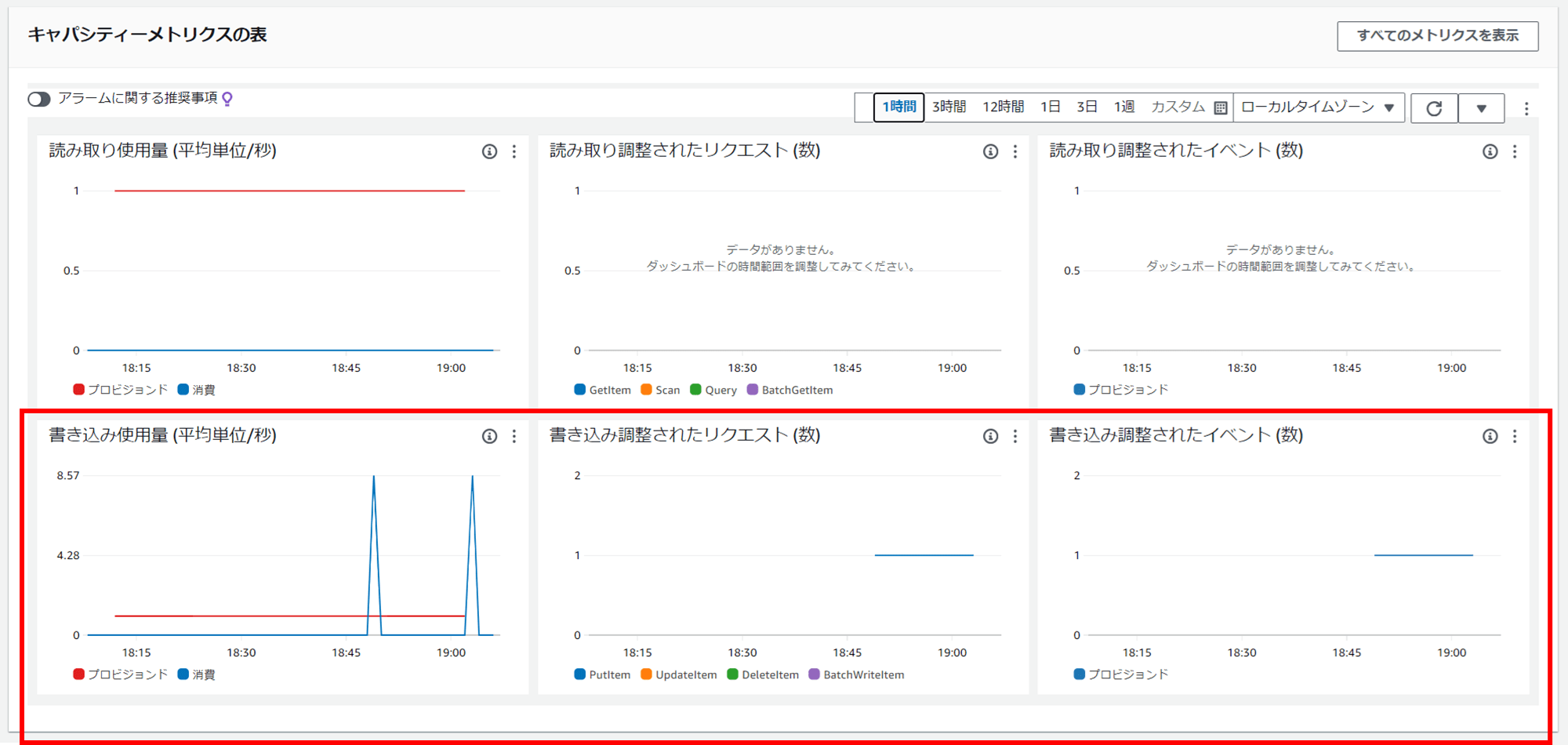
「調整された」という日本語が分かりにくいのですが、スロットリングのことです。英語にした方が分かりやすいかもしれませんね。
最後に、DynamoDB のテーブルに書き込んだアイテムの様子を見てみましょう。DynamoDB コンソールで対象のテーブルを開き、右上の「テーブルアイテムの探索」というオレンジのボタンをクリックすると、格納されたアイテムが表示できます。
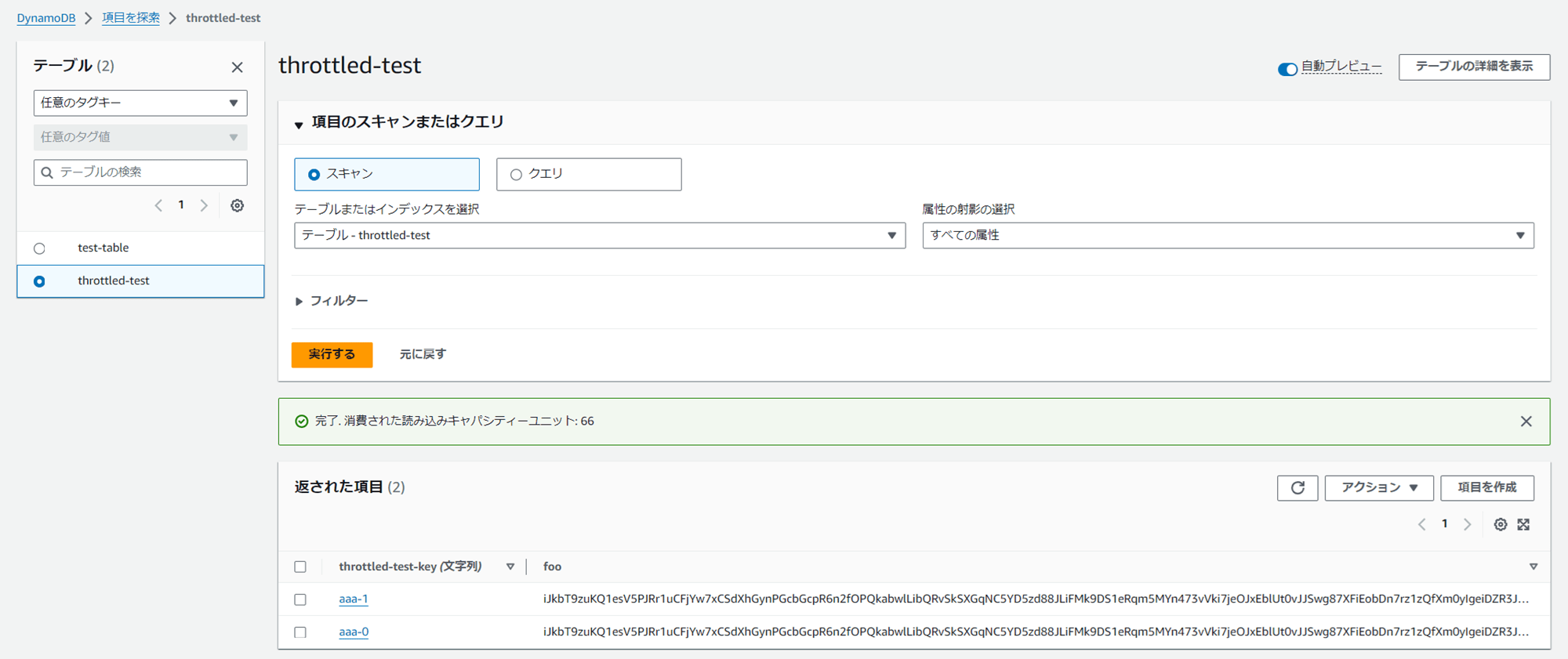
2 アイテム書き込まれていますね。foo には長いランダム文字列が二つ、同じものが格納されているのが分かります。
おわりに
DynamoDB のスロットリングの挙動のイメージがつかめたと思います。ついでに Lambda の仕様や、AWS SDK で DynamoDB にアクセスする方法も勉強できました。どなたかのお役に立てば幸いです。
余談
余談なのですが、Boto はアマゾン川に生息する淡水イルカの名前から取られているそうです。なんだか可愛く感じられてきましたね!ドキュメントにこういうことが書かれているとちょっと楽しいです。
Boto (ボトと発音) という名前は、アマゾン川に自生する淡水イルカに由来しています。
Python と Boto3 による Amazon DynamoDB のプログラミング - Amazon DynamoDB
日本語ではアマゾンカワイルカと呼ぶそうで、口が長くピンク色をしている珍しいイルカだそうです。
参考







